At this point one could also include the VMR Normalization workflow but the document input list will show only the unpreprocessed document in the current version of the program (this will be changed in a future update). In case that the preprocessed document is intended to serve as input for the VMR normalization sub-workflow, it is currently necessary to first specify the VMR preprocessing workflow by clicking the OK button of the dialog. The dialog can then be re-entered without having to run the VMR preprocessing workflow since now the expected generic name will be available when selecting the VMR Normalization workflow. The snapshot below shows the generated genric name as the output of VMR preprocessing that is selected as input for the VMR normalization workflow (although the preprocessing workflow has not been executed yet).
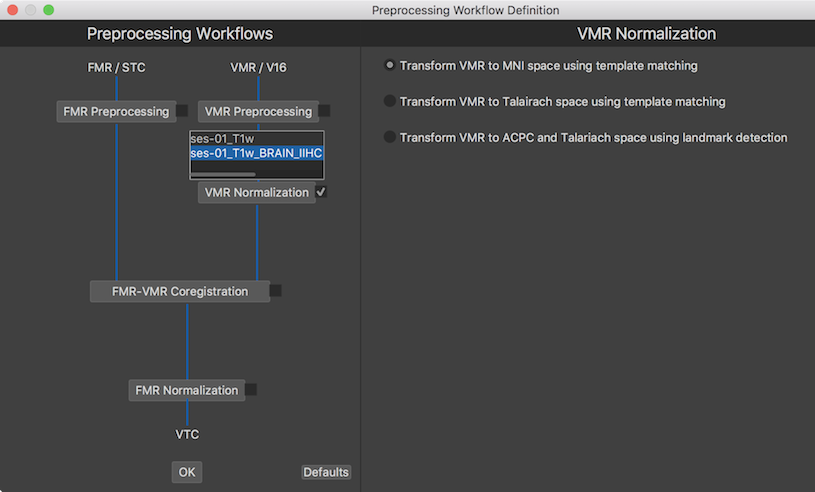
The mutually exclusive VMR normalization workflow options are shown on the right side. The Transform VMR to MNI space using template matching option is seleected as default and used in this example. The Transform VMR to Talairach space using template matching option transforms the selected data set(s) into near-Talairach space using the template matching approach used for MNI normalization. The Transform VMR to ACPC and Talairach space using landmark detection option transforms the selected VMR document(s) to ACPC and Talairach space using the automatic landmark-based normalization approach. After clicking the OK button in the Preprocessing Workflow Definition dialog, both anatomical workflows (VMR Preprocessing in row 6 and VMR Normalization in row 7) are defined but not yet executed (see snapshot below).
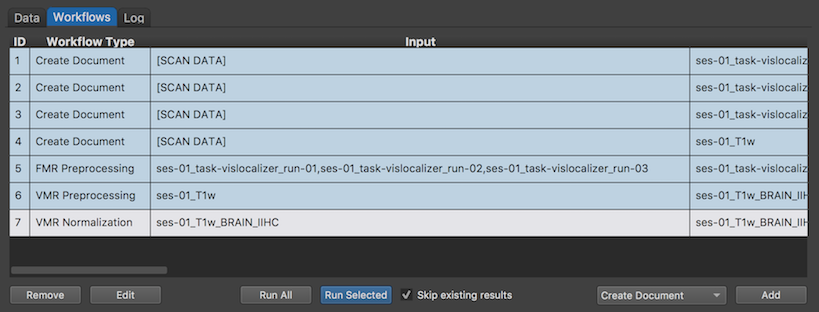
The screenshot above shows that the resulting VMR document name after preprocessing will be identified by the appended "_BRAIN_IIHC" string indicating that the data set will contain the brain (surrounding tissue will be removed) and that it will have undergone intensity inhomogeneity correction. This generic name serves as input for the normalization workflow creating a new VMR document with the appended string "_MNI" indicating that the anatomical data set is transformed to MNI space.
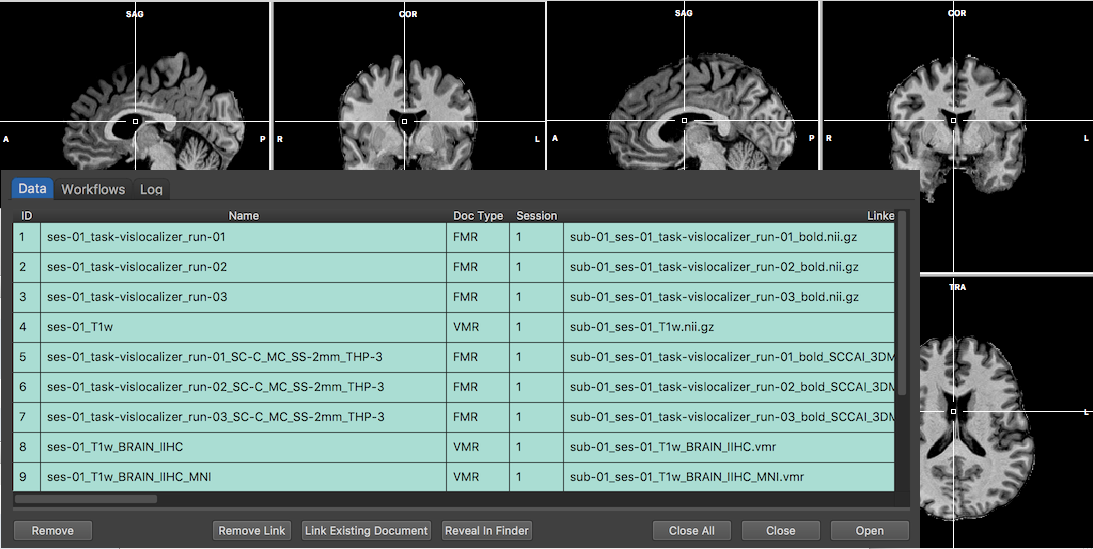
The screenshot above shows the resulting VMR documents after running the two workflows. Since the normalization workflow does not yet produce a workflow report, the preprocessed and normalized VMR documents for the two subjects of the example data have been opened in the multi-document area of BrainVoyager by double-clicking (short for clicking the Open button) the respective MNI documents (entry 9 in subject-specific data table) for both subjects (VMR of sub-01 on left, sub-02 on right side). As can be seen, both data sets have been successfully preprocessed and normalized in MNI space.