BrainVoyager v23.0
Functional Normalization Workflow
The FMR normalization workflow transforms (preprocessed) functional FMR data files into VTC files in coregistered anatomical space. While this space can be the "native" space of the intra-session 3D T1 anatomical data set, the transformation usually goes beyond native sapce to produce functional VTC data files in MNI, Talairach or ACPC space. To run successfully, this workflow requires that the coregistration workflow has been performed as well as a VMR normalization workflow (except in case one wants to bring the functional data only in the anatomical scanner (native) space).
Creating and Connecting the Workflow
As other workflows, the functional normalization workflow can be created using the Create Workflows dialog that can be launched by using the Create button in the Workflows tab of the Data Analysis Manager window. In the appearing dialog, the Functional Normalization entry need to be selected (see screenshot below). Note that one could add other workflows at the same time but here we describe the creation of each workflow in a separate step.
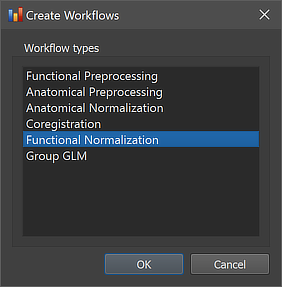
After clicking the OK button, the new workflow appears in the Workflows tab (see figure below). The ID column indicates that the unique identifier '5' has been assigned to this workflow; the column Type shows the generic name "Functional Normalization" for the assigned (and stored) type ID (5); the column Name shows the default name "func-normalization" that has been assigned to this workflow, which can be changed in the Workflow dialog. The empty cells in the Input and Output columns indicate that the instantiated functional normalization workflow is not yet ready to be executed since no data connections have been made. To connect the workflow to input data, the Connect Workflows dialog is used, which can be invoked by clicking the Connect button in the Workflows tab.
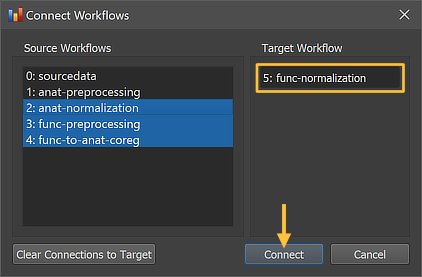
The Connect Workflows dialog shows in the Source Workflows list on the left side all available data sources including the NIfTI files in the sourcedata folder and the generated outputs of other workflows A specific workflow is identified by its unique ID and its name ("[workflow-ID]: [workflow-name]"). On the right side the target workflow is displayed to which data can be connected to, which is the currently selected functional normalization workflow. Since usually the output of the functional preprocessing workflow is used as input for the normalization workflow, the "3: func preprocessing" workflow is selected in the Source Workflows list. Furthermore the "4: func-to-anat-coreg" workflow is selected since the output transformation (IA and usually FA) files are needed to bring the functional data into the scanner (native) space of the anatomical data. From this space, the same normalization step can be applied to the functional data as has been applied to the anatomical data (here: MNI normalization), and therefore the "2: anat normalization" workflow is also selected.
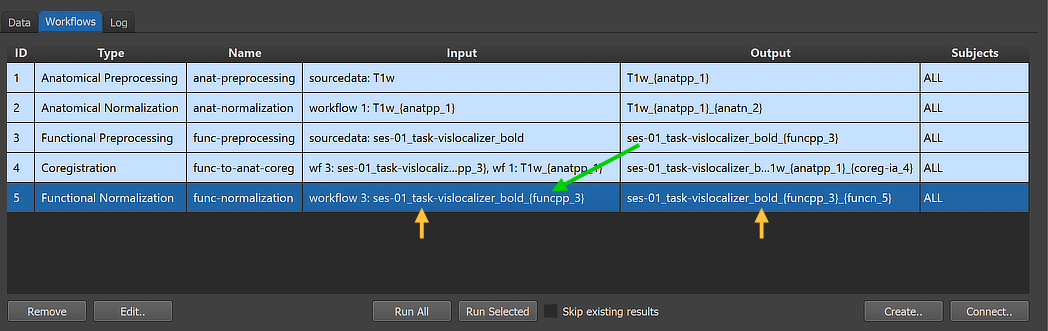
After clicking the Connect button in the Connect Workflows dialog, the established connection is made and the workflow entry is updated accordingly. The arrows in the figure above indicate that the functional normalization workflow will use the output of the functional preprocessing workflow 3 as input (the coregistration and normalization anatomical sources are not shown here but can be inspected in the Workflow dialog, see below). The generated output file name in the Output column corresponds to the name of the preprocessed functional data that is extended with the substring '_{funcn_5}' of the new (normalization) workflow, which will be replaced with the normalization variant used (here "MNI"). Note that he generic output name now contains two processing variables, "{funcpp_3}" and "{funcn_5}".
Inspecting and Editing Workflow Settings
In order to inspect and eventually change settings, such as parameters that control the processing, one can invoke the Workflow dialog by double-clicking the workflow entry in the Workflows table or by clicking the Edit button below the table after selecting the workflow.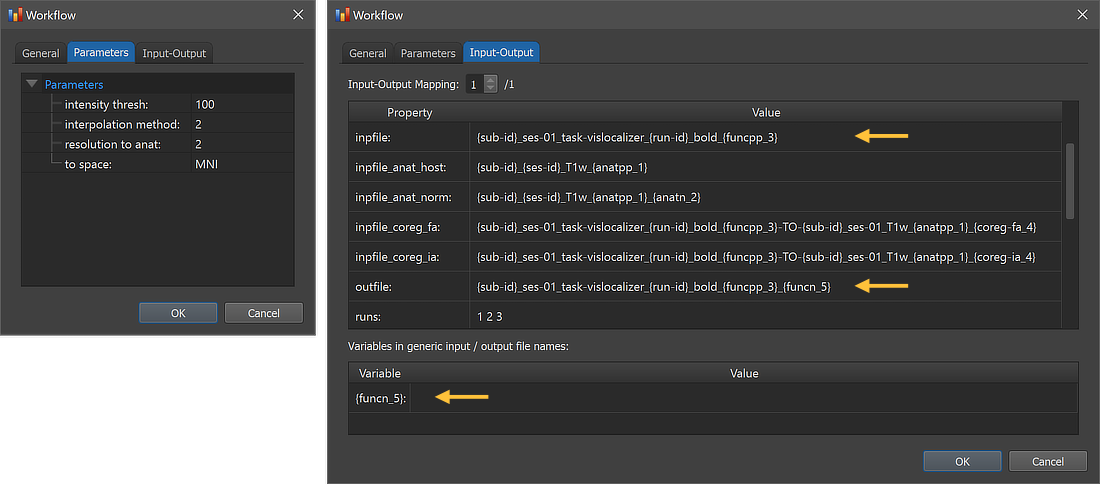
The figure above shows the contents of the Parameters tab (left) and he Input-Output tab (right) of the Workflow dialog. The Parameters tab shows the parameters specific for the selected workflow, which can be inspected as well as changed. The default preprocessing options set the interpolation method to '2', which corresponds to sinc interpolation; other possible values are '0' for nearest neighbor and '1' for trilinear interpolation. The resolution to anat parameter is set to '2' as default, which sets the voxel size to twice the one of the anatomical dataset (2mm x 2mm x 2mm). The to space parameter must match the transformation of the anatomical normalization workflow specified as one of the input sources (MNI). The intensity thresh parameter is set to '100' as default, which will exclude voxels that have low (background) intensity values since measured (brain) tissue intensities in original scanner data will have typically values beyond 1000.; this intensity masking can be turned off by setting the value to '0'.
The right side of the figure above shows the Input-Output tab, which displays information related to the established data flow connection(s). Each connection (if more than 1) can be viewed by changing the Input-Output Mapping number. The inpfile and outfile fields (see arrows) show the generic name of the functional files with the subject and session substrings replaced by (loop) variables (enclosed by curly braces '{}'). As mentioned above, the outfile entry has an extended file name that adds the substring "_{funcn_5" ('n' for normalization) to the substring from the preprocessing workflow "_{funcpp_3}"; the processing variable "{funcn_5}" is also visible in the Variables in generic input / output file names field. When running the workflow, processing variables will be replaced with concrete values (substrings) that depend on the included processing steps and parameter settings of the respective workflows. When inspecting the variables section in the dialog after running the workflow, the concrete values of all processing variables will be displayed. Note that variables (and their values if available) will be handed over to any subsequent workflow so that file names with additional substrings can be constructed before any workflow has been executed. Note that besides the generic name for the main functional input files (3 runs per session (1( per subject), the generic coregistration file names from the specified Coregistration workflow are also listed in the inpfile_coreg_ia and inpfile_coreg_fa entries. Furthermore the generic name of the specified anatomical normalization workflow is shown in the inpfile_anat_norm entry. The additional entry inpfile_anat_host has been automatically added by retrieving the input workflow of the anatomical normalization workflow, which is the native (scanner) space representation that will be used to "host" the normalization process, i.e. the appropriate same-session native space anatomical file will be loaded and visible in the multi-document window for each subject (and session) when running the functional normalization workflow.
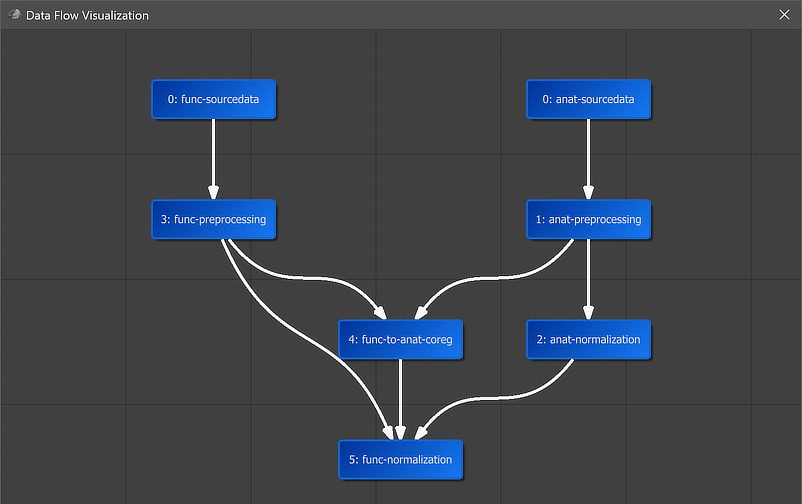
A global overview of the established connection is graphically displayed when clicking the Data Flow button in the main toolbar of the Data Analysis Manager (see screenshot above). In the appearing visualization the "5: func-normalization" workflow is placed below the "4: func-to-anat-coreg" workflow, the "2: anat-normalization" workflow and the "func preprocessing" workflow, which all serve as input to the functional normalization workflow. It is also placed in the middle of anatomical and functional data since it uses both types of data as input. The arrows connecting the nodes indicate the established anatomical and functional processing pipeline.
Running the Workflow
After selecting the workflow in the Workflows tab (single-click on its row in the table), the prepared functional normalization workflow can be executed using the Run Selected button (or the Run All) button). In case that the Skip existing results option has been turned on, the program will not process datasets in case that the expected output data are already available. This option is useful (saving time) in case that one adds more subjects to a project and wants to preprocess only the newly added ones. An alternative way to restrict the workflow to specific subjects is to select the desired subset of subjects in the Subjects field in the General tab of the Workflow dialog.
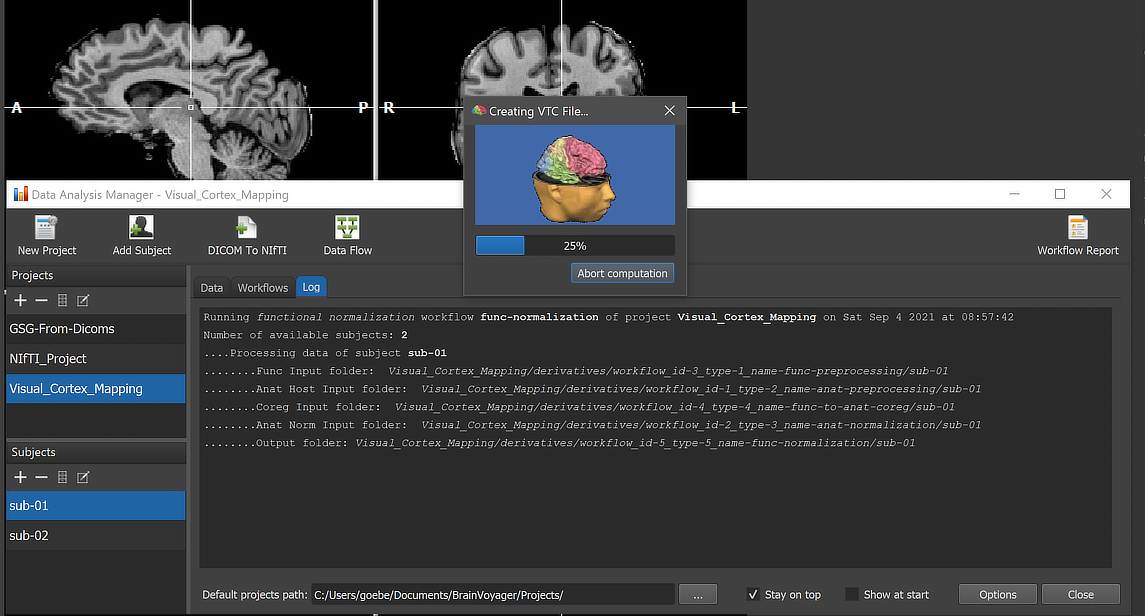
When running a workflow, the program displays the progress of data processing in the Log tab of the Data Analysis Manager window. The screenshot above captures a moment during functional (MNI) normalization (VTC creation) of one of the runs of subject 'sub-01'.
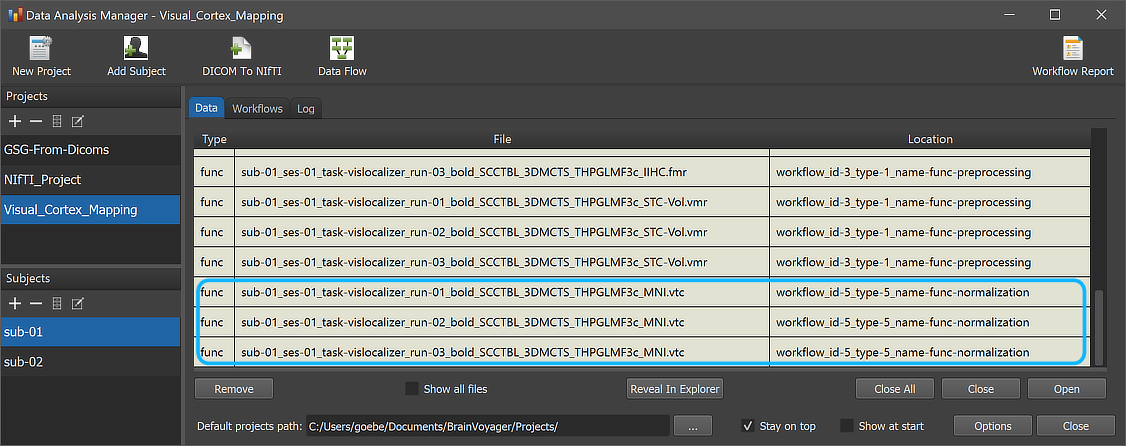
After the workflow has finished processing, the main produced data files can be inspected by switching to the Data tab of the Data Analysis Manager. The rectangle in the screenshot above highlight the newly added entries (3 MNI normalized VTC files) for the selected subject but the same output will be available for all subjects (here only 2) in case that processing was successful. The produced output file name in the File column have the substring "_MNI" as compared to the preprocessed functional input file names shown in rows higher up in the Subject Data table.
Processing variables and their values are now also stored in the "workflowinfo.json" file inside the functional normalization workflow folder that has been updated when running the workflow. The variables can be inspected by opening the Workflow dialog (see screenshot below).
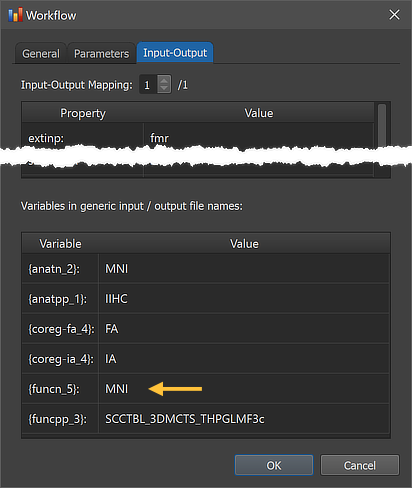
The Variables in generic input / output file names table now shows value "MNI" for the '{funcn_5}' variable of the functional normalization workflow (see arrow) as well as the values of all other processing variables appearing in the generic input and output file names in the Input-Output Mapping table (not shown here but see earlier screenshot).
The Location column of the Data table of the Data Analysis Manager indicates that the normalized functional (VTC) files are stored inside the created workflow directoy (under the derivatives folder of the project); the name of the workflow folder 'workflow_id-5_type-5_name-func-normalization' contains the unique workflow ID ('5'), its type ('5') and its name ('func-normalization'). Note that you can link the normalized VTC file to the currently open anatomical file (which should be in the same normalized space, preferentially from the same subject or a standard MNI template brain) by simply double-clicking its row in the Data table or by clicking the Open button below the table after selecting the respective table row. The location on disk of the generated file can be shown in the Finder (macOS) or Explorer (Windows) by clicking the Reveal in Finder or Reveal in Explorer button. The figure below shows the full generated directory tree of the workflow on disk.
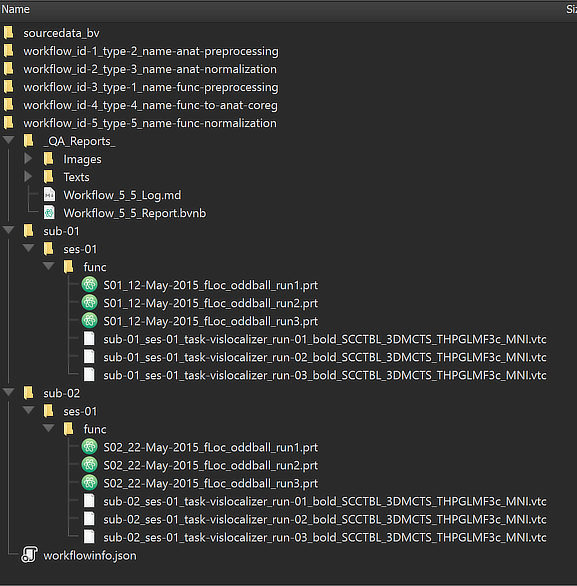
This view illustrates that the workflow organization on disk replicates the BIDS directory tree for the relevant data (here "func" folders). Next to the three produced functional runs in MNI space, each "func" folder also contains the respective protocol files that are copied over from the input functional workflow. Besides the BIDS sub-directories for each subject, the "_QA_Reports_" folder is also stored inside the workflow directory containing the full log (Markdown) text file and the generated quality report as a BrainVoyager notebook (see below), which will be shown automatically when the workflow has completed. The workflow report can also be shown at a later time by clicking the Workflow Report icon in the main toolbar of the Data Analysis Manager after selecting the respective entry in the Workflows table.
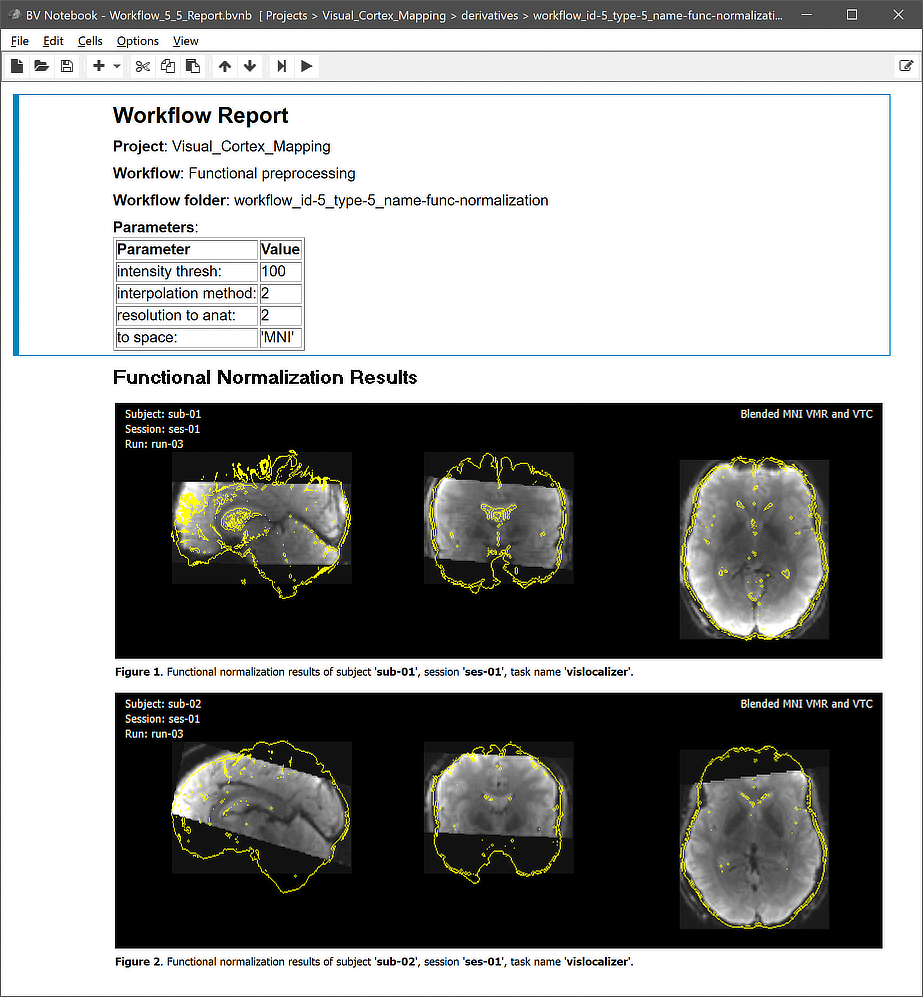
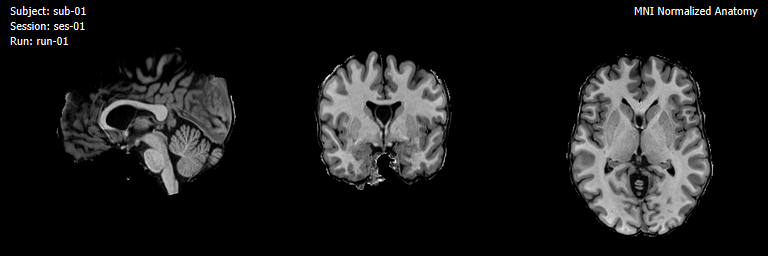
Note that the figures generated per subject are actually animations (not visible in screenshot above) showing, for each run, the normalized anatomy (VMR), the normalized functional dataset (VTC) and a blended version of contours of the anatomy over the functional dataset. The animation embedded in the quality report for subject 'sub-01' is shown below.
Copyright © 2023 Rainer Goebel. All rights reserved.